Remove Duplicate Action: removeDuplicate
The removeDuplicate action under the CSVHandle function removes duplicate rows from a CSV file based on a specified column. The resulting file, with duplicates removed, is saved at the specified output path. The operation result (true/false) is stored in a variable for further use.
Note: Ensure that the file being used is not open during the execution of the Case to avoid errors or conflicts.
Example: Suppose you have a CSV file named EmployeeRecords.csv, located at C:\Data, with the following data:
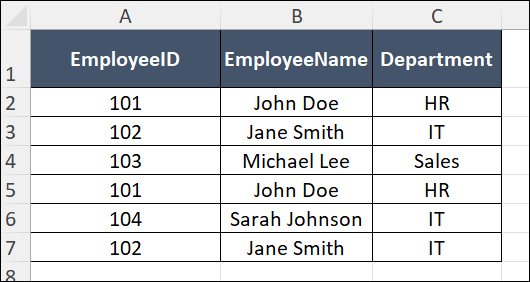
You want to remove duplicate rows based on the EmployeeID column and save the updated data in a new file named UniqueEmployeeRecords.csv.
Steps to Configure:
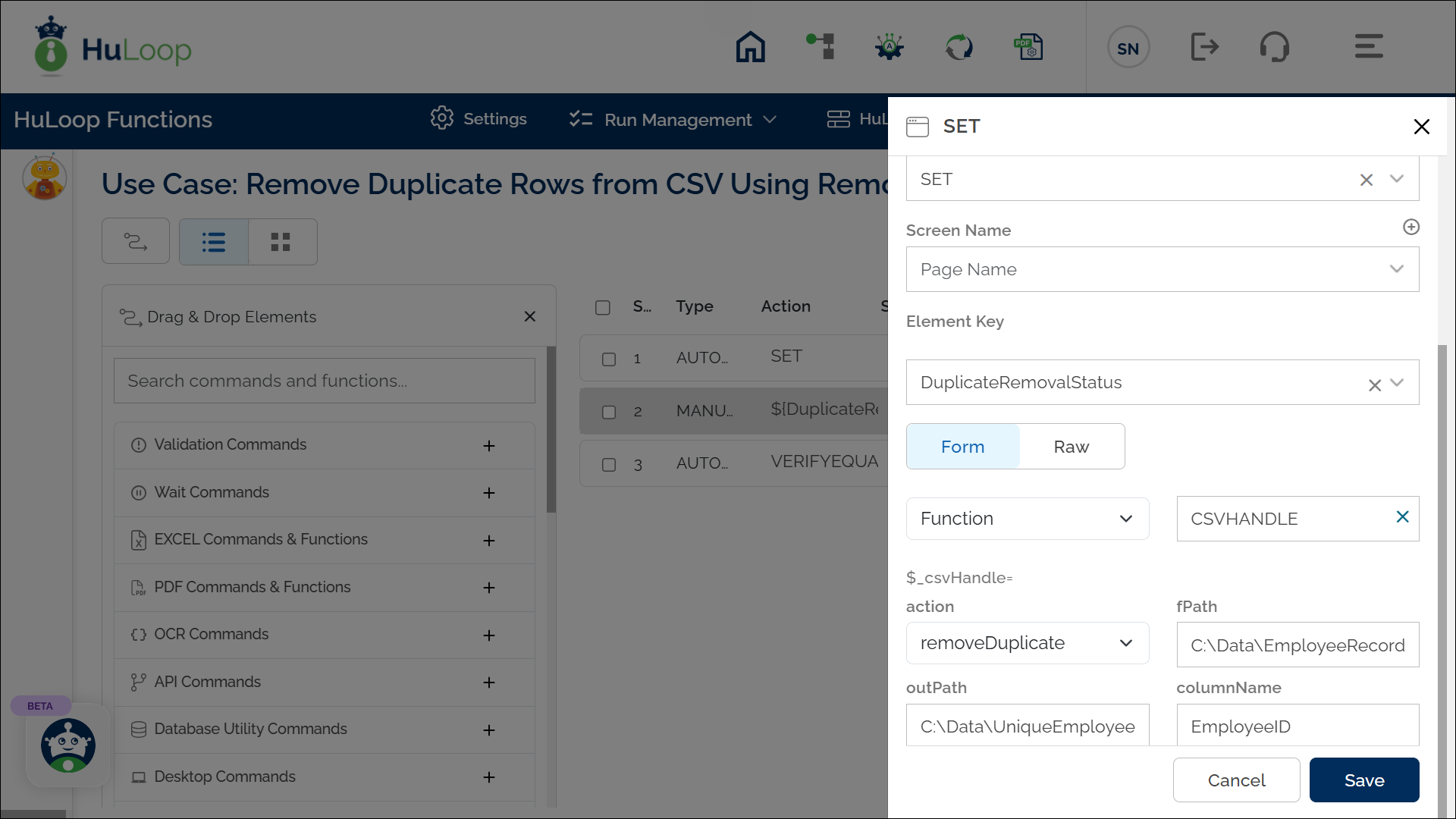
- Select SET from the Action dropdown.
- Enter a variable name in the Element Key field (e.g., DuplicateRemovalStatus). This variable will store the result of the operation (true/false).
- Click on Form, select Functions, and choose CSVHANDLE.
- In the action field, select removeDuplicate and provide the following parameters:
- fPath: Specify the path to the source CSV file (e.g., C:\Data\EmployeeRecords.csv).
- outPath: Specify the path to save the updated file (e.g., C:\Data\UniqueEmployeeRecords.csv).
- columnName: Enter the column name to identify duplicates (e.g., EmployeeID).
- Click Save.
Outcome on Execution:
- The updated CSV file (UniqueEmployeeRecords.csv) will contain the following data:
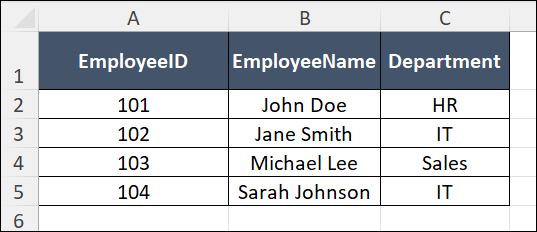
- If the operation is successful, the variable (e.g., DuplicateRemovalStatus) stores true.
- If the operation fails (e.g., invalid file path or column name), the variable stores false.
- This variable can be referenced in subsequent automation steps using the syntax ${VariableName} (e.g., ${DuplicateRemovalStatus}).