Extract Pdf Action: extractpdf
The extractpdf action is used to extract specific/split pages from a source PDF file and save them into a new destination PDF file. This functionality is beneficial when working with large documents where only certain sections need to be shared or processed further.
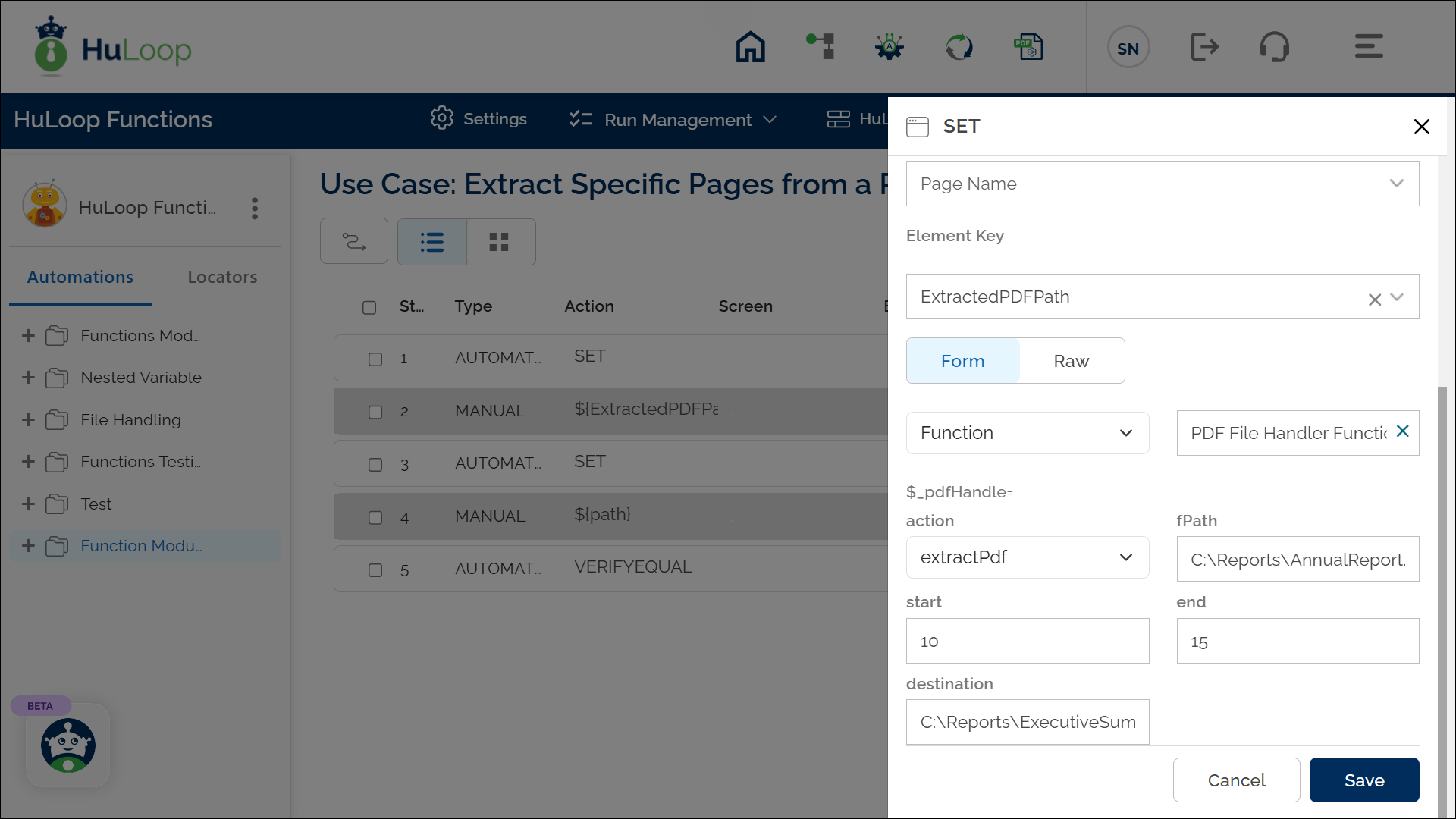
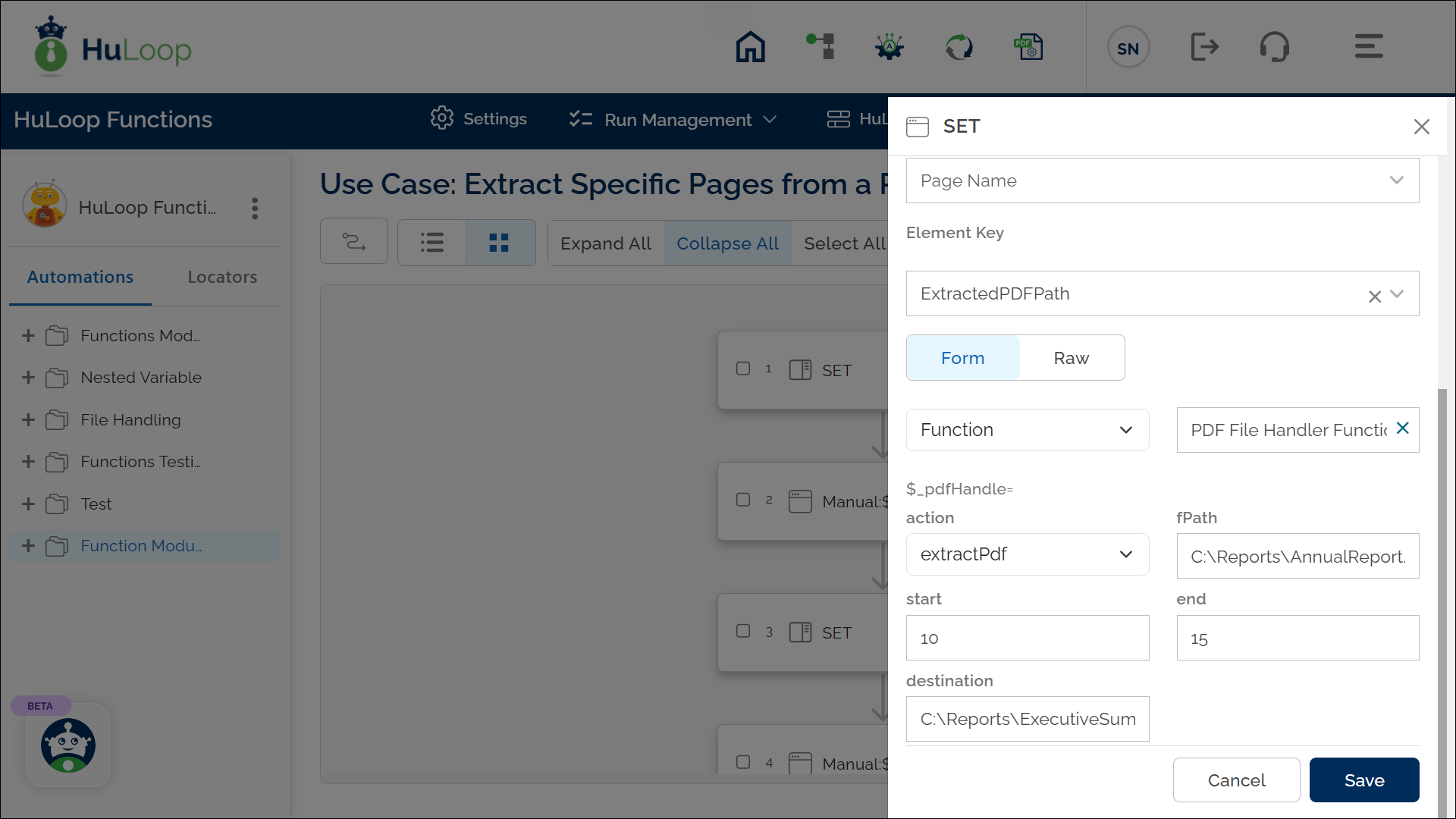
Example: You have a 50-page PDF file named AnnualReport.pdf and want to extract pages 10 to 15 into a new file named ExecutiveSummary.pdf.
Steps to Configure:
- Add a new step.
- Select SET from the Action dropdown.
- Enter a variable name in Element Key (e.g., ExtractedPDFPath). This variable will store the path to the newly created PDF file.
- Click on Form, select Functions, and choose PDF File Handler Functions.
- In the actionfield, select extractpdf and provide the following parameters:
- fPath: Specify the source PDF file path (e.g., C:\Reports\AnnualReport.pdf).
- start: Define the starting page number to extract (e.g., 10).
- end: Define the ending page number to extract (e.g., 15).
- destination: Provide the destination file path where the extracted pages will be saved (e.g., C:\Reports\ExecutiveSummary.pdf).
- Click Save.
Outcome on execution:
- Pages from the specified range (start to end) are copied into the destination file.
- The destination file path is stored in the variable defined in the Element Key field. This variable can be referenced in subsequent steps of the automation process using the syntax ${VariableName} (e.g., ${ExtractedPDFPath}).
Notes:
Last updated: Sep 11, 2025- If the destination file already exists, it will be overwritten.
- Paths should be absolute and properly formatted to avoid errors during execution.