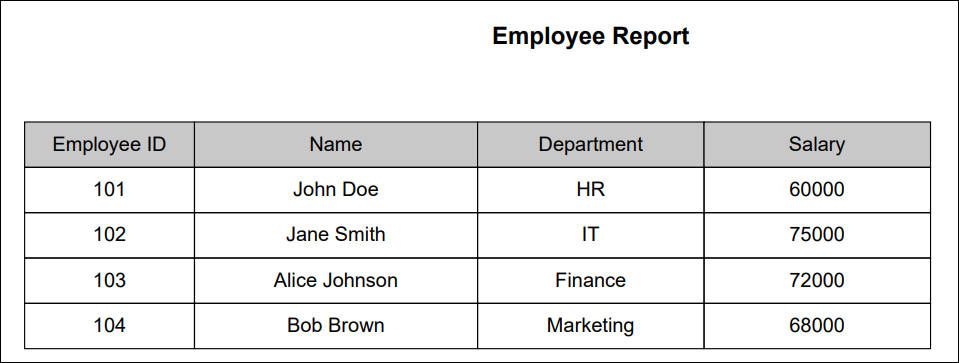
GETPDFTABLEDATA Function: getPDFTableData
The GETPDFTABLEDATA function extracts specific data from a table within a PDF file based on column and row identifiers. It enables precise data retrieval from structured PDF documents, eliminating manual search and extraction. The extracted value is stored in a variable, which can be used in subsequent automation steps.
Example: You need to extract the Salary of an employee whose Employee ID is 102 from the EmployeeReport.pdf file stored in C:\Data\
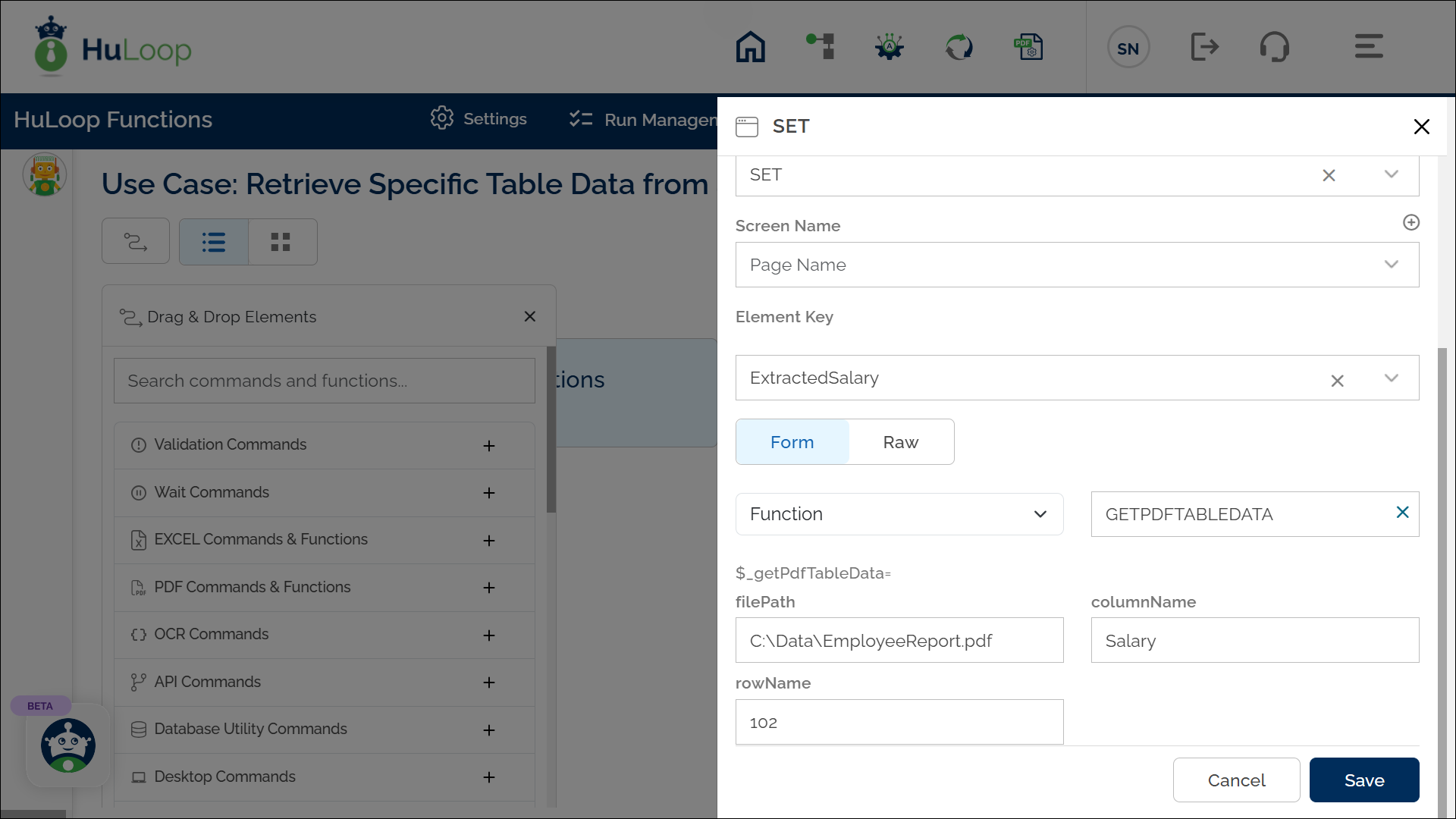
Steps to Configure:
- Add a new step.
- Select SET from the Action dropdown.
- Enter a variable name in Element Key (e.g., ExtractedSalary). This variable will store the retrieved value.
- Click on Form, select Functions, and choose GETPDFTABLEDATA
- Provide the following parameters:
- filePath: Specify the full path of the PDF file (e.g., C:\Data\EmployeeReport.pdf).
- columnName: Enter the column name from which data should be extracted (e.g., Salary).
- rowName: Enter the row identifier to locate the specific entry (e.g., 102).
- Click Save.
Note: While the steps for adding an Action are identical in both views, the display of the steps changes:
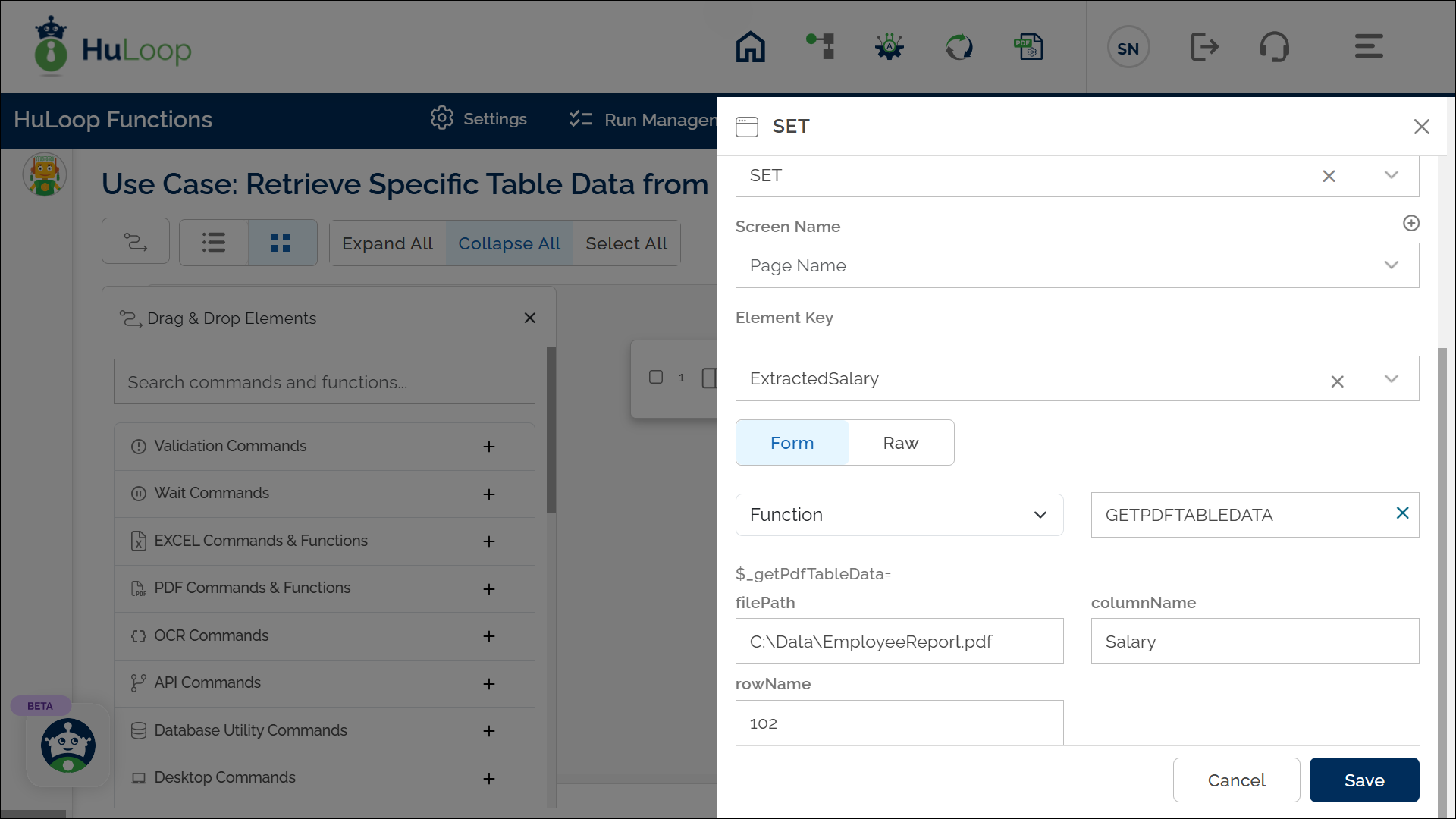
Outcome on Execution:
- After executing the function, the variable ${ExtractedSalary} will store 75000, which is the salary of Employee ID 102.
- You can then use ${ExtractedSalary} in later automation steps.