getText Action: getText
The getText action extracts content from specific pages of a PDF file.
This action is ideal for use cases where targeted text or image extraction from specific PDF pages is required for automation workflows.
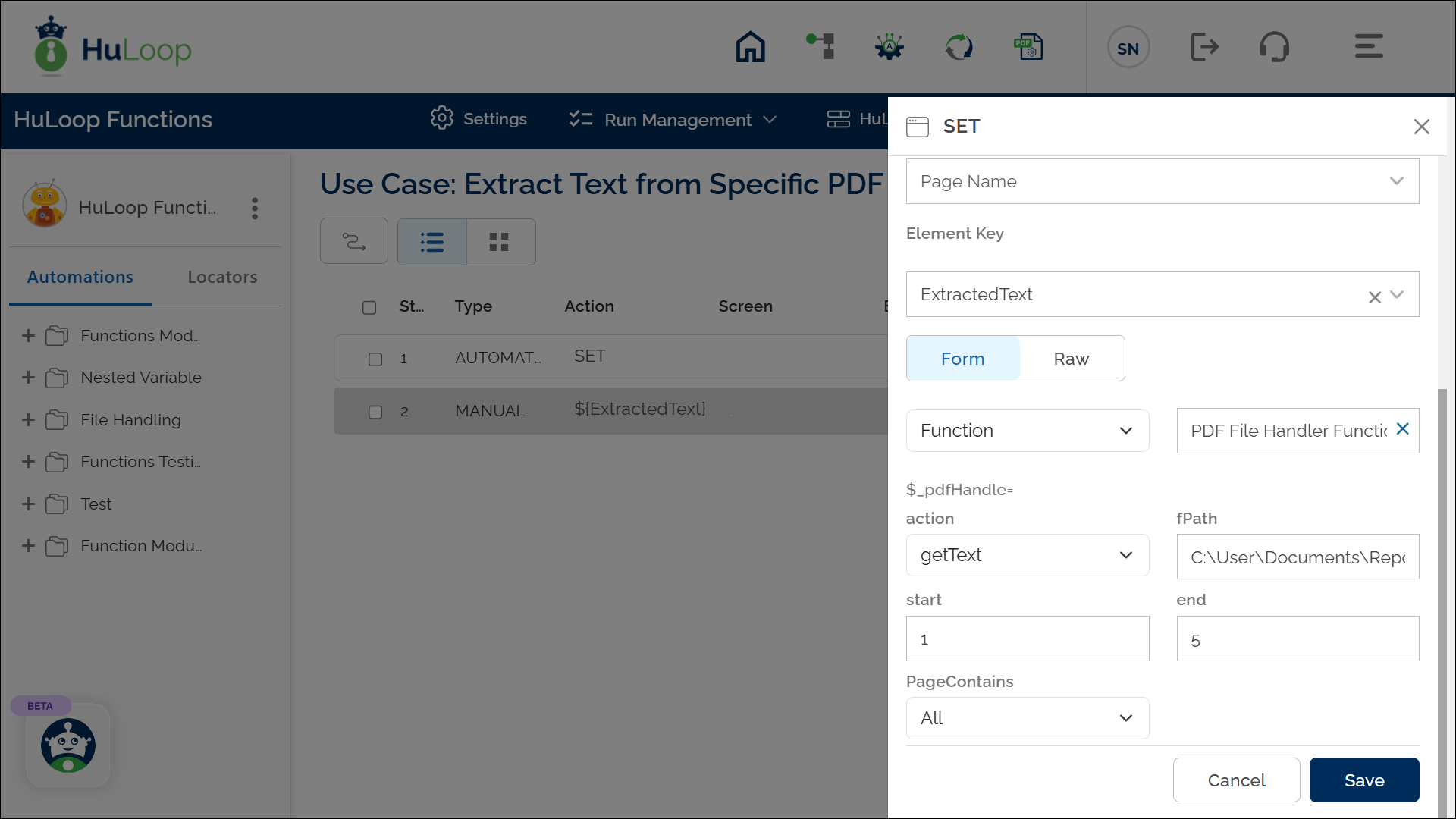
Example: You need to extract the text from pages 1 to 5 of the Report.pdf file located in “C:\User\Documents\”.
Steps to Configure:
- Add a new step.
- Select SET from the Action dropdown.
- Enter a variable name in Element Key (e.g., ExtractedText). This variable will store the extracted text.
- Click on Form, select Functions, and choose PDF File Handler Functions.
- In the action dropdown, select getText.
- Provide Parameters:
- fPath: Specify the full path of the PDF file to extract text from (e.g., C:\User\Documents\Report.pdf).
- start: Define the starting page number for the extraction (e.g., 1).
- end: Define the ending page number for the extraction (e.g., 5).
- Page Contains: Select what type of content to include from the dropdown:
- Text: Extract only text content.
- Images: Extract only images.
- All: Extract both text and images.
- Click Save.
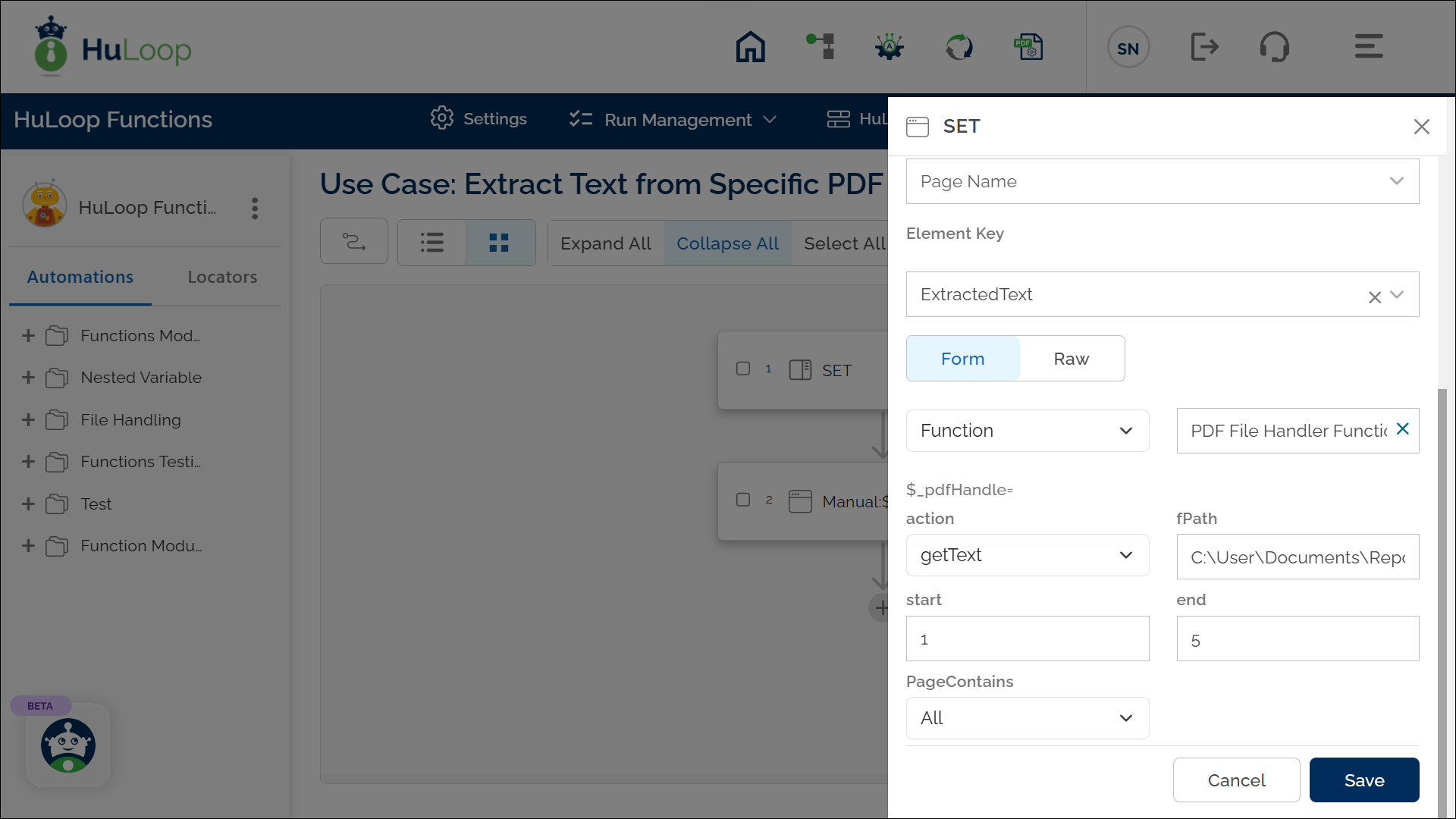
Outcome on execution:
- If the file contains the following text on pages 1 to 3:
- Page 1: This is a test document.
- Page 2: It demonstrates the GetText function.
- Page 3: Automation simplifies text extraction.
- The variable ${ExtractedText} will store the text from page 1 to page 3 as shown:
- This is a test document.
- It demonstrates the GetText function.
- Automation simplifies text extraction.
- Use the variable syntax ${VariableName} (e.g., ${ExtractedText}) to access this text in later steps.
Last updated: Oct 6, 2025