Read And Store PDF Table Data: pdftable
The Read And Store PDF Table Data function extracts tabular data from a PDF file based on specified top and bottom identifiers. The extracted table data is stored in a variable, which can be used for validation or further automation steps. This function helps in retrieving structured data from PDFs without manual intervention.
Example: Suppose you have a PDF file named EmployeeDetails.pdf located in the folder C:\Data. You need to extract the salary details from the table present in this document. The table is identified by the Top Identifier “Employee Salary Details” and the Bottom Identifier “End of Table.” The extracted data should be stored in a variable for validation in subsequent steps.
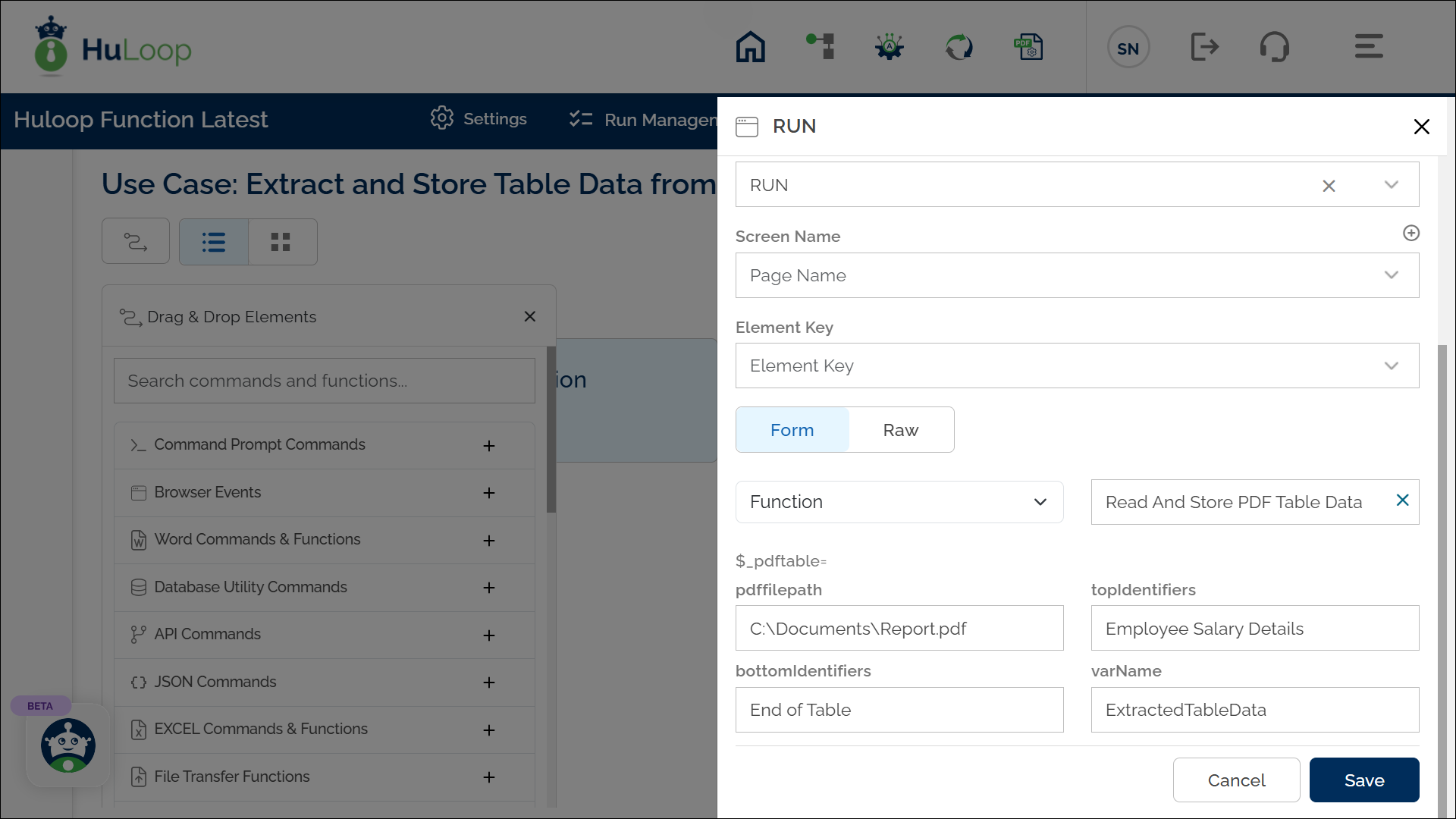
Steps to Configure:
- Add a new step.
- Select RUN from the Action dropdown.
- In the Parameters section, click Edit.
- Click on Form, select Functions from the dropdown, and choose Read And Store PDF Table Data.
- Provide the following parameters:
- pdffilepath: Enter the full path of the PDF file containing the table (e.g., C:\Documents\Report.pdf).
- topIdentifiers: Specify a unique text that appears above the target table to help locate it (e.g., Employee Salary Details).
- bottomIdentifier: Specify a unique text that appears below the target table to define its boundary (e.g., End of Table).
- varName: Define a variable (e.g., ExtractedTableData) to store the retrieved table data.
- Click on the Save icon.
Note: While the steps for adding an Action are identical in both views, the display of the steps changes:
Outcome on Execution:
- The defined variable (e.g., ExtractedTableData) will store the entire table data, which can be used for further validation in automation workflows.
- You can reference this variable using syntax ${ExtractedTableData} in subsequent steps.